
To get started with natural language processing NLP, we will look at some definitions, wins and bottlenecks in NLP. Lastly, we will learn some preprocessing techniques like tokenization, lemmatization and stemming. This article includes code examples in the python programming language.
I teach the Natural Language Processing track at AI Saturdays in Abuja. I hope this blog post and NLP series would serve as a refresher for my students and other learners! 💖
What is Natural language Processing, NLP?
Natural Language Processing, is an interdisciplinary scientific field that deals with the interaction between computers and the human natural language.
Some NLP use case scenario includes;
Speech recognition, Natural language understanding (NLU), Natural language generation, Sentiment analysis, Conversational systems, Machine translation (MT), Information Retrieval systems e.t.c
NLP Wins and Bottlenecks
Let’s start by looking at successes and bottlenecks in NLP.
Wins
Modern computer techniques with natural language are being used today to improve lives and increase efficiency at workplaces.
Email providers now have NLP powered apps that can scan emails to correct misspellings, extract information and compose emails with better grammar for us.
A good example is Google smart compose, which offers suggestions as you compose an email.
Another popular example is Grammarly, a writing assistant that helps you compose writings with better grammar and checks for spelling errors.
Social media platforms, with our permission, collect bits of our daily lives and feed us tailored advertisements.
Speech-powered devices like the Amazon Echo and Google Home can understand and interpret our human natural language commands.
NLP is super interesting! Isn’t it? 🚀 😍
Some of the bottlenecks
Computers are built to follow certain rules of logic flow, but humans are not, and so is our communication.
Some of the tasks that are easy for humans is extremely difficult for the computer.
How can a computer tell the difference between sarcasm and the original intent of a sentence?
Human natural language and communication are ambiguous for the computer.

Our goal is to apply an algorithm to a natural language dataset to train it to understand, interpret, and eventually perform a useful task.
For us to achieve this, we need to;
- Assess the grammatical rule of our language (Syntactic)
- Understand and interpret its meanings (Semantics)
What are the five categories of natural language processing NLP systems?
The five basic natural language processing categories include lexical analysis, syntactic analysis, semantic analysis, discourse integration, parsing, and pragmatic analysis.
Lexical Analysis
Lexical analysis entails trying to understand the meaning of words while also considering their usage context and how they relate to other words.
Lexical analysis is often the first step when dealing with NLP data pipelines.
Syntactic Analysis
Words are arranged in a way that grammatically makes sense.
Semantic Analysis
Semantics is the meaning expressed by a given input text.
Semantic analysis is one of the difficult tasks in natural language processing because it requires complex algorithms to understand and interpret the meaning of words and the overall structure of the given sentence.
Semantic analysis may include techniques such as:
- Entity Extraction
- Natural Language Generation
- Natural Language Understanding
- Machine Translation
Discourse analysis
Discourse analysis is the process of looking at how we use language in different contexts. It’s used to understand what someone might mean even if they don’t say it explicitly, i.e., text interpretation.
Pragmatic Analysis
Natural Language Processing with Python Examples
Text Normalization
Before we can start building anything useful, we have to preprocess/prepare our datasets.
The goal of stemming and lemmatization is to reduce inflected word forms to their base form.
Inflection: letters can be added to adjectives, verbs, nouns and other parts of speech to express meaning and for other grammatical reasons.
For example;
Base words: Bus, City, Criterion, Bureaucracy
Inflection: Buses, Cities, Criteria, Bureaucratization
Lemmatization and Stemming use different approaches to reduce inflection.
Stemming
Stemming cut off letters from a word to reduce it to a stem.
PorterStemmer and LancasterStemmer are two popular algorithms for performing stemming on the English language
How to Stem words using NLTK
#import the nltk package
import nltk
#nltk downloader
nltk.download('punkt')
let’s try out both PorterStemmer (Porter’s algorithm 1980) and LancasterStemmer algorithm
from nltk.stem import PorterStemmer
from nltk.stem import LancasterStemmer
#create an object of class PorterStemmer and #LancasterStemmer
porter_stem = PorterStemmer()
lancaster_stem = LancasterStemmer()
#find the stem of these words
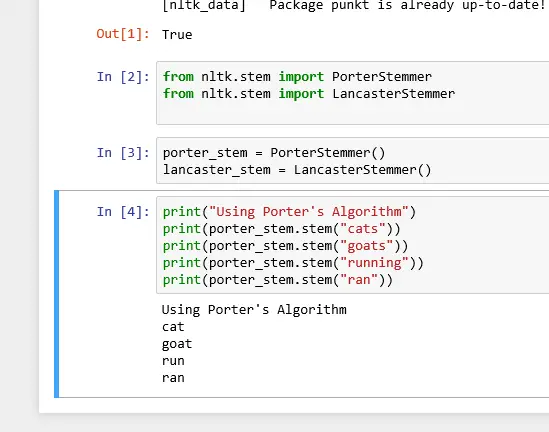
print("Using Porter's Algorithm")
print(porter_stem.stem("cats"))
print(porter_stem.stem("goats"))
print(porter_stem.stem("running"))
print(porter_stem.stem("ran"))
print("Using Lancaster's Algorithm")
print(lancaster_stem.stem("Zebras"))
print(lancaster_stem.stem("democracy"))
print(lancaster_stem.stem("bureaucracy"))
print(lancaster_stem.stem("perfection"))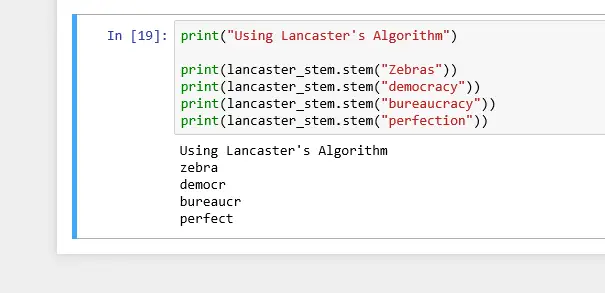
Notice the base words produced by stemming, after cutting off ‘acy’ in democracy and bureaucracy. ‘democr’, and ‘bureaucr’ is not a meaningful English word.
Lemmatization
Unlike stemming that only cut off letters, lemmatization takes a step further; it considers the part of speech and possibly its meaning to reduce it to its correct base form (lemma).
Lemmatization most times produce an actual word.
Lemmatization searches a corpus to match inflected words and base words.
A good corpus example is the WordNet corpus.
# import WordNet Lemmatizer
from nltk.stem import WordNetLemmatizer
#create an object of class WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
# a denotes adjective, a word that modifies a noun
# v denotes verb
# n denotes noun
print("lemma of 'quickly' is ", lemmatizer.lemmatize("quickly", pos="a"))
print("lemma of 'asked' is ", lemmatizer.lemmatize("asked", pos="v"))
print("lemma of 'cables' is ", lemmatizer.lemmatize("cables", pos ="n")) 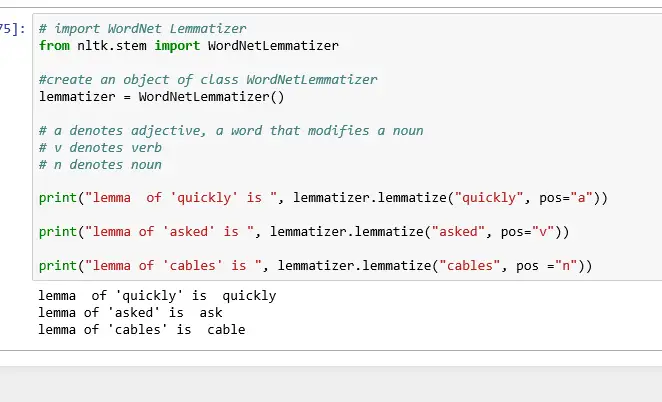
Tokenization
Tokenization describes splitting/breaking down a text document into smaller units.
A token is a unit of text in the document.
For example;
“This sentence can be broken down into a small unit of words.”
“This” “sentence” “can” “be” “broken” “down” “into” “a” “small” “unit” “of” “words”
#import word tokinize
from nltk.tokenize import word_tokenize
text = "The Lazy dog JUMPED over the fence"
tokens = word_tokenize(text)
print(tokens)
we can tokenize into sentences too
#import sentence tokenize
from nltk.tokenize import sent_tokenize
text = "The Lazy dog JUMPED over the fence. The cat was chasing it. Lagos traffic is on another level"
tokens = sent_tokenize(text)
print(tokens)
More examples
Before we can find the root of words in a sentence, we have to use tokenization to split the sentence and find each root’s root.
text = '''Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules. Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.'''
Tokenize the sentence into words
from nltk.tokenize import sent_tokenize, word_tokenize
def tokenize_Sentence(text):
token_words=word_tokenize(text)
return token_words
print(tokenize_Sentence(text))
Perform Porter’s algorithm
def porter_algorithm(tokenize_Sentence):
text = []
for word in tokenize_Sentence:
text.append (porter_stem.stem (word))
text.append(" ")
stem_words = "".join(text)
return stem_words
print (porter_algorithm(tokenize_Sentence(text)))
Compare results with the Lancaster algorithm.
def lancaster_algorithm(tokenize_Sentence):
text = []
for word in tokenize_Sentence:
text.append (lancaster_stem.stem (word))
text.append(" ")
stem_words = "".join(text)
return stem_words
print (lancaster_algorithm(tokenize_Sentence(text)))
Let’s lemmatize the sentence
def WordNet_Lemmatizer(tokenize_Sentence):
text = []
for word in tokenize_Sentence:
text.append (lemmatizer.lemmatize(word, pos = "a"))
text.append(" ")
lemma_words = "".join(text)
return lemma_words
print (WordNet_Lemmatizer(tokenize_Sentence(text)))
Try this: Example on a File
Using shakespeare-hamlet.txt in the Gutenberg corpora
List of Natural Language Processing (NLP) Python, R and Java Libraries and Frameworks
- NLTK
- spaCy
- Stanford CoreNLP
- TextBlob
- Gensim
- Pattern
- Polyglot
- PyNLPl
- Vocabulary
We would look at more concepts and topics in other blog posts
Glad you made it to the end 🔥
Download the Jupyter notebook from Github
Would you mind sharing your comments and questions on the comment box
Looking for a hands-on coding publication to learn new skills in Cloud Computing, Data Engineering, and MLOps, visit TreapAI
Read more posts on machine learning.
Further Reading on Natural Language Processing
- Get started with Natural Language Processing
- Morphological segmentation
- Word segmentation
- Parsing
- Parts of speech tagging
- breaking sentence
- Named entity recognition (NER)
- Natural language generation
- Word sense disambiguation
- Deep Learning (Recurrent Neural Networks)
- WordNet
- Language Modeling
Interested in learning how to build for production? check out my publication TreapAI.com




{kind=link}
Thanks for this tutorial its very helpful
Between lemmatization and stemming which is faster?
When do I use one against the other?
I enjoyed this lesson
thanks!
I enjoyed this lesson. Very articulate and easy to grasp
thanks, kay!
very useful introduction especially for beginner in the nlp
Making NLP look really easy !!!
feeling like jumping on it already
I enjoyed to this post understood something
[…] Get started with Natural Language Processing NLP […]