In this tutorial we would look at some Part-of-Speech tagging algorithms and examples in Python, using NLTK and spaCy
What is Part-of-Speech (POS) tagging?
POS tagging is the process of assigning a part-of-speech to a word.
Part of Speech reveals a lot about a word and the neighboring words in a sentence.
If a word is an adjective, its likely that the neighboring word to it would be a noun because adjectives modify or describe a noun.
Having an intuition of grammatical rules is very important.
Earlier we discussed the grammatical rule of language. Let’s look at the syntactic relationship of words and how it helps in semantics.
For example, let’s say we have a language model that understands the English language
How can our model tell the difference between the word “address” used in different contexts?
"I would like to address the public on this issue" "We need your shipping address"
"address" in the first sentence is a Verb whereas "address" in the second sentence is a Noun
Identifying the part of speech of the various words in a sentence can help in defining its meanings.
In the example above, if the word “address” in the first sentence was a Noun, the sentence would have an entirely different meaning. Its part of speech is dependent on the context.
More examples
The cat will die if it doesn't get enough air The gambler rolled the die
"die" in the first sentence is a Verb "die" in the second sentence is a Noun
The waste management company is going to refuse (reFUSE - verb /to deny/) wastes from homes without a proper refuse (REFuse - noun /trash, dirt/) bin
POS tagging is a process that is used for assigning tags to a word or words. These tags indicate the part of speech for the word and often other grammatical categories such as tense, number and case.
POS tagging is very key in Named Entity Recognition (NER), Sentiment Analysis, Question & Answering, Text-to-speech systems, Information extraction, Machine translation, and Word sense disambiguation.
It is useful in labeling named entities like people or places.
e.g We traveled to the US last summer US here is a noun and represents a place "United States"
In lemmatization, we use part-of-speech to reduce inflected words to its roots

POS tagging Algorithms
Hidden Markov Model (HMM); this is a probabilistic method and a generative model
Maximum Entropy Markov Model (MEMM) is a discriminative sequence model.
Recurrent Neural Network
Hidden Markov Model (HMM)
A brief look on Markov process and the Markov chain
A Markov process is a stochastic process that describes a sequence of possible events in which the probability of each event depends only on what is the current state.
If we want to predict the future in the sequence, the most important thing to note is the current state.
The state before the current state has no impact on the future except through the current state.
HMM is a sequence model, and in sequence modelling the current state is dependent on the previous input.
Part-of-Speech Tagging examples in Python
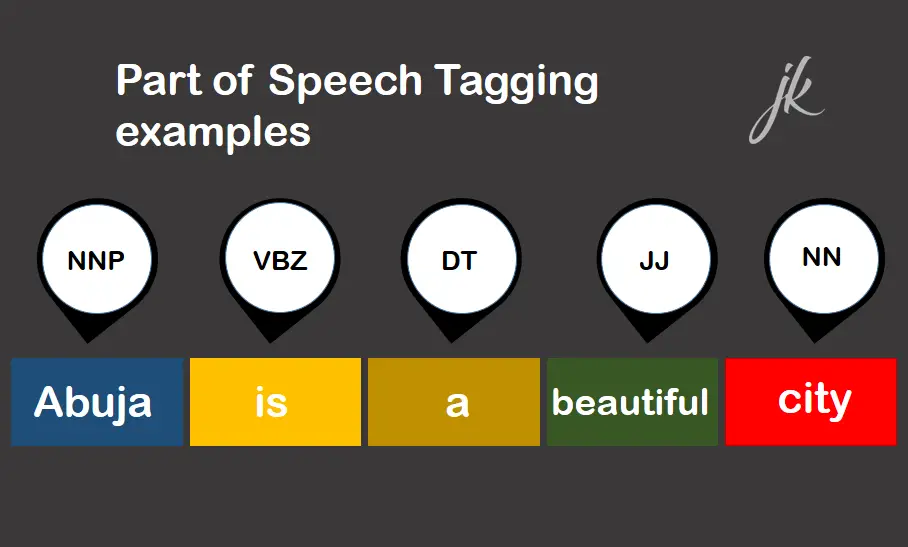
To perform POS tagging, we have to tokenize our sentence into words.
Both the tokenized words (tokens) and a tagset are fed as input into a tagging algorithm.
Tagset is a list of part-of-speech tags. POS tags are labels used to denote the part-of-speech
Using NLTK
Import NLTK toolkit, download ‘averaged perceptron tagger’ and ‘tagsets’
‘averaged perceptron tagger’ is NLTK pre-trained POS tagger for English
import nltk
from nltk import word_tokenize
nltk.download( 'averaged_perceptron_tagger')
nltk.download( 'tagsets')First, we tokenize the sentence into words.
text = "Abuja is a beautiful city"
tokens = word_tokenize(text)
tokenstryout the pos_tag in NLTK on our tokens
from nltk import pos_tag
pos_tag (tokens)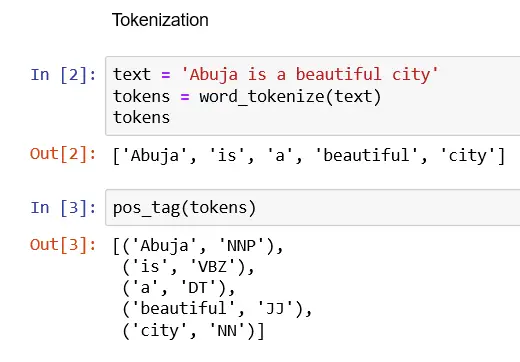
text2 = '''Washing your hands is easy, and it’s one of the most effective ways to prevent the spread of germs. Clean hands can stop germs from spreading from one person to another and throughout an entire community—from your home and workplace to childcare facilities and hospitals.
Follow these five steps every time.
Wet your hands with clean, running water (warm or cold), turn off the tap, and apply soap.
Lather your hands by rubbing them together with the soap. Lather the backs of your hands, between your fingers, and under your nails.
Scrub your hands for at least 20 seconds. Need a timer? Hum the “Happy Birthday” song from beginning to end twice.
Rinse your hands well under clean, running water.
Dry your hands using a clean towel or air dry them.'''
tokens2 = word_tokenize(text2)
pos_tag (tokens2)
NLTK has documentation for tags, to view them inside your notebook try this
import nltk.help
nltk.help.upenn_tagset('VB')Using spaCy
Import spaCy and load the model for the English language ( en_core_web_sm).
import spacy
nlp = spacy.load("en_core_web_sm")text = '''Washing your hands is easy, and it’s one of the most effective ways to prevent the spread of germs. Clean hands can stop germs from spreading from one person to another and throughout an entire community—from your home and workplace to childcare facilities and hospitals.
Follow these five steps every time.
Wet your hands with clean, running water (warm or cold), turn off the tap, and apply soap.
Lather your hands by rubbing them together with the soap. Lather the backs of your hands, between your fingers, and under your nails.
Scrub your hands for at least 20 seconds. Need a timer? Hum the “Happy Birthday” song from beginning to end twice.
Rinse your hands well under clean, running water.
Dry your hands using a clean towel or air dry them.'''
doc = nlp(text)Tokenization
[token.text for token in doc]POS tagging
for token in doc:
print (token.text, token.pos_, token.tag_)More example
text = "Abuja is a beautiful city"
doc2 = nlp(text)dependency visualizer
displacy.render(doc2, style="dep", jupyter=True)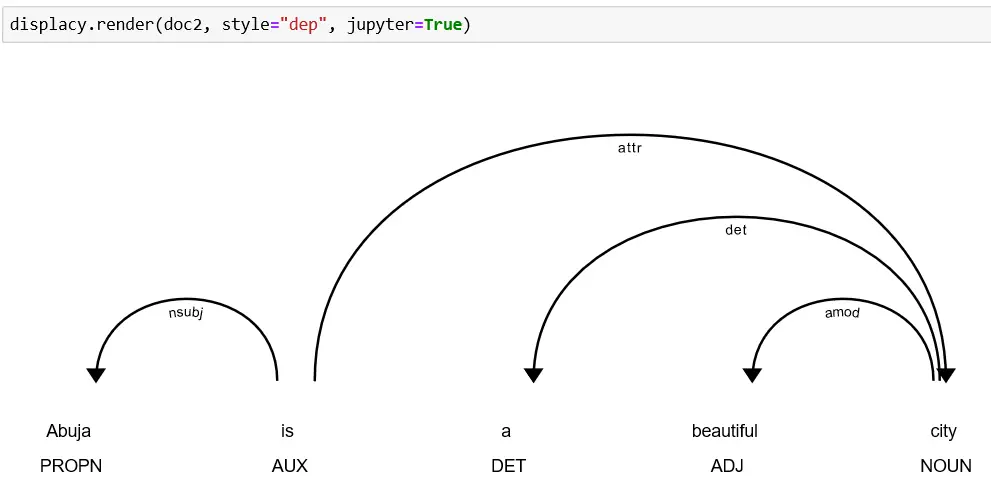
Different types of POS tagging include:
the different types of POS tagging are;
- Rule-Based: In rule-based pos tagging, a dictionary is designed to contain words with a list of tags associated with each word. A set of rules are designed to guide the tagger. These rules are either learned or manually designed. An example rule might say “if an unknown word links a noun to another word, tag it as a preposition”
- Statistical: Text corpora are being used to calculate probabilities. Given a sequence of words, the most probable tag is selected. These are called stochastic or probabilistic taggers. Typical models include n-gram, Hidden Markov Model, and Maximum Entropy Model.
- Transformation-Based: Rules are automatically created from data. This combines rule-based and stochastic methods. In tagging, broad rules are applied to categorize content, and then narrower ones are added to improve precision.
- Neural Net: Recurrent neural networks (RNN) and bidirectional long short-term memory (LSTM) are two neural network architectures that can be used for part of speech tagging. If they’re used properly, they provide great results.
Hey! you made it to the end 😍
Download the Jupyter notebook from Github
Looking for more resources;
Follow our NLP series
Further Reading on Natural Language Processing
- Get started with Natural Language Processing
- Morphological segmentation
- Word segmentation
- Parsing
- Parts of speech tagging
- breaking sentence
- Named entity recognition (NER)
- Natural language generation
- Word sense disambiguation
- Deep Learning (Recurrent Neural Networks)
- WordNet
- Language Modeling
Interested in learning how to build for production? check out my publication TreapAI.com

